Hashing tests
The tested techniques are the following:
- hashtable: plain old hashtable with chaining
- hashtable-sf: plain old hashtable with chaining, but the Jenkins hash is
replaced by
SuperFastHash from Paul Hsieh
- hashtrie64: hashtrie with HASHSHIFT == 6 (default)
- hashtrie32: hashtrie with HASHSHIFT == 5
- hashtrie16: hashtrie with HASHSHIFT == 4
- hashtrie8: hashtrie with HASHSHIFT == 3
- hashtrie4: hashtrie with HASHSHIFT == 2
- hashtrie-var0: hashtrie with different HASHSHIFT values:
level-0 = 14, level-1 = 3, level-2 ... = 2
- hashtrie-var1: hashtrie with different HASHSHIFT values:
level-0 = 8, level-1 = 6, level-2 ... = 4
- hashtrie-var2: hashtrie with different HASHSHIFT values:
level-0 = 12, level-1 = 6, level-2 ... = 2
- hasharray8: plain old hashtable where a chain of tuple[8] is used to
avoid clashes
- hasharray4: plain old hashtable where a chain of tuple[4] is used to
avoid clashes
- shared_node: shared node fast hash from
Fast Hash Table Lookup Using Extended Bloom Filter: An Aid to Network
Processing by Song et al., SIGCOMM'05
Notes:
- According to Paul Hsieh, the SuperFastHast is ~66% faster than the
Jenkins hash.
Without CPU-dependent optimization, there is no big difference between the
two hash functions. CPU-dependent optimization (on my laptop:
-march=i686 -mtune=pentium4) does indeed speed up sfhash:
| Calculating the hash value of 3 words |
| jhash: | 150 cyc, 75 ns |
| sfhash: | 137 cyc, 69 ns |
It is about ~8% gain in speed: the difference comes from the fact
that the ~66% was measured calculating the hash key of 256 bytes and
not 12 bytes. So when taking into account IPv6, it might be well worth
to consider replacing jhash with sfhash.
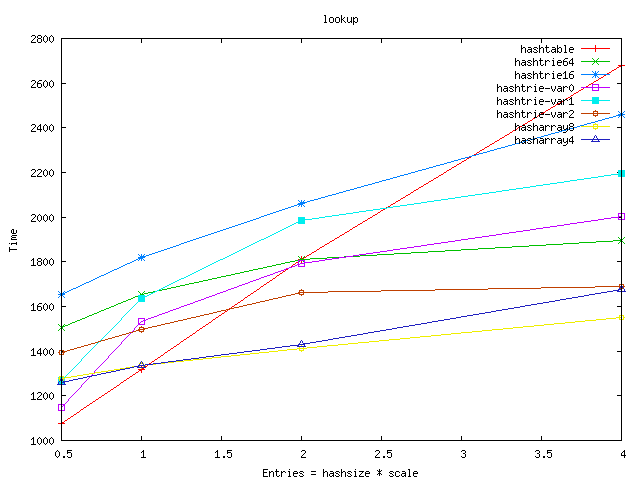
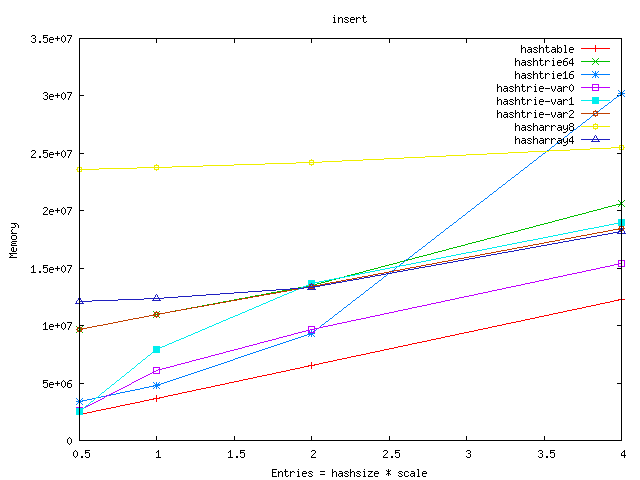
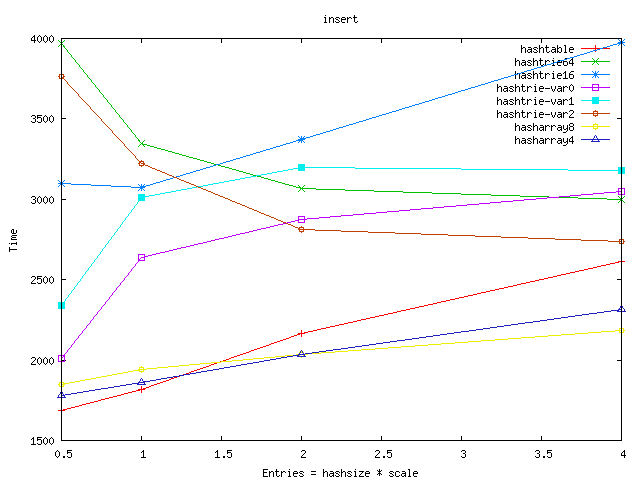
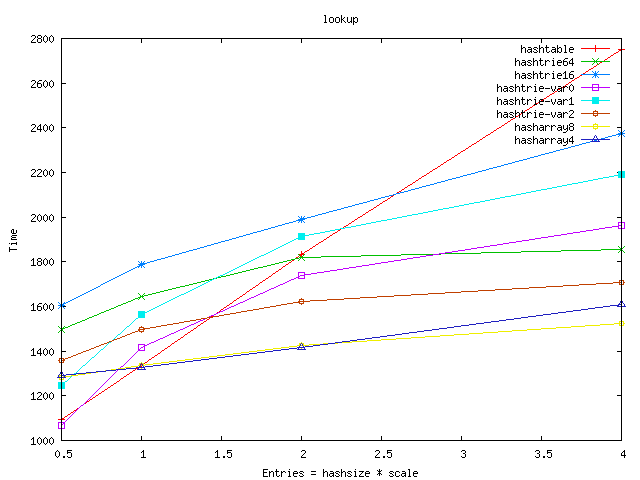
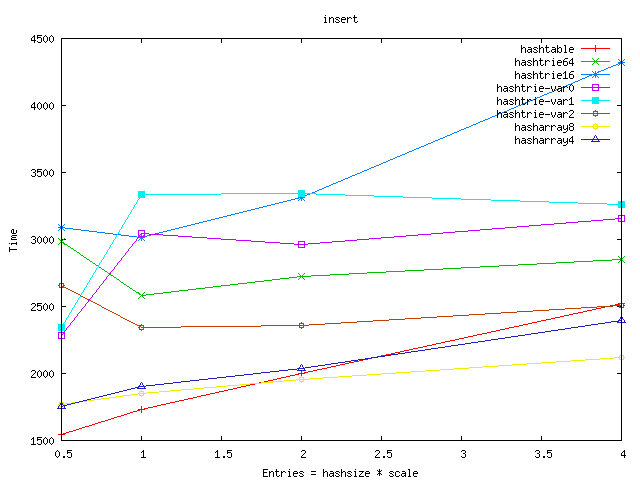
- hashtrie64 wastes a lot of memory. My theory is that the hash
functions work "too good" and there are too many leaves with single or few
entries. Therefore I lowered the base hashsize, hoping that thus we can
lessen the wasted bytes. It worked - but it also deteriorated the
insert/lookup speed :-(.
- I can't really explain that strange extra memory requirement for
hashtrie32. Some coincidence in hashsize/entry size?
- The hashtrie-var variants use different size of hashes at the different
levels. hashtrie-var2 is better both in the memory requirement and
lookup/insert speed than the plain hashtries.
- Hasharrays use an array of tuples to avoid clashes. They are very good
in insert/lookup: we have got a fast path because the full 32bit hash key is
stored in the tuple and we have got a second fast path too because the clashing
tuples are on the cacheline :-). We pay by memory for the speed, but
hasharray4 is not so bad - it is quite near to the best hashtrie-var variant.
- The shared node fast hash is a straightforward implementation of the
algorithm from the cited article. The disappointing results may be
due to the faults in my implementation.
- I just messed with Martin's code: all kudos to him!
The source code can be downloaded from the netfilter svn repository:
svn co https://svn.netfilter.org/netfilter/trunk/hashtrie.
From the graphs below I left out the worst results: shared_node, hashtrie4,
hashtrie8, hashtrie32 (and hashtable-sf is left out also). The full results
can be seen on this page.
Memory requirements:
Time: insert random entries
Time: lookup random entries
Time: insert DoS entries
Time: lookup DoS entries